What is Data Warehouse?
A data warehouse is a data integration system designed to gather business intelligence by consolidating and analysing large amounts of data from multiple sources. As a central repository or data store, it enables comprehensive data analysis and helps extract meaningful insights from cross-functional business areas.
Data warehouses play a crucial role in decision-making and meeting the evolving needs of customers. By sourcing a vast amount of current and historical data from sources like ERP software and analysing it through data mining techniques, data warehouses serve as ideal tools for complex query and reporting needs.
Advantages of Data Warehouse
For the successful implementation of a data warehouse, the ETL process provides a solid foundation, making the data warehouse ready to gain cutting-edge insights and optimise business processes. Take a look at the following data warehouse benefits to understand its potential.
- Data Integration
A data warehouse combines data from various databases and internal and external systems into a common unified source. This data is transformed into a structured format that allows faster analysis and reporting.
- Improved Business Analytics
As a data warehouse pulls data from all potential sources needed for analysis, it makes your business analytics process more comprehensive and suitable for making informed decisions.
- High Data Quality
For a data warehouse to be effective and deliver the expected analytical results, the data undergoes cleaning before it is stored in the data warehouse, significantly enriching the data quality.
- Faster Query Times
The core focus behind setting up a data warehouse is to enable business users to access data quickly from large datasets, analyse it, and generate relevant answers to complex analytical queries.
-
Handle Multi-Condition Queries
A data warehouse utilises tools like an OLAP engine to process queries with multiple logical conditions, besides giving users the flexibility to slice and dice data and gain the insights they are looking for.
Characteristics of a Data Warehouse
A data warehouse is noted for its unique characteristics, i.e. it is subject-oriented, integrated, time-variant and non-volatile. Let’s understand what they mean.
→ Subject-oriented
Using data marts, a data warehouse can focus on specific business domains, such as finance, sales, customer relationship management, and inventory, simplifying decision-making for respective business areas.
→ Integrated
A data warehouse consolidates data from multiple sources and departments into a common source. This data integration ensures that the data is uniformly structured and formatted before analysis.
→ Time-variant
As data warehouses store vast historical data for extended periods, they can track past performance with relative ease and identify long-term trends to forecast future business outcomes.
→ Non-volatile
Despite the continuous addition of new data, the data warehouse remains stable. This inherent nature prevents unexpected modifications in the data structure, making it trustworthy for analysis.
Data Warehouse Architecture
The architecture of a data warehouse has a significant impact on its performance and scalability. While there is no one-size-fits-all solution, the exact design and architecture will depend on custom business requirements. Warehouse architecture is broadly classified into one-tier, two-tier and three-tier models. Let’s find out how each model differs from the others.
→ One-tier Architecture
Here, users have a direct connection with the data sources, which means that the data can be easily accessed without needing a complicated IT infrastructure for running queries and analysis. As the warehouse is located on a single server, it is simple and cost-effective to set up and manage. Businesses with limited data volume prefer this approach.
→ Two-tier Architecture
The distinguishing aspect of the two-tier architecture is that the data undergoes an ETL process before being loaded into the data warehouse. This second layer is a crucial intermediate step that ensures that the data is clean and consistent for analysis. It is suitable for businesses with slightly complex processing requirements.
→ Three-tier Architecture
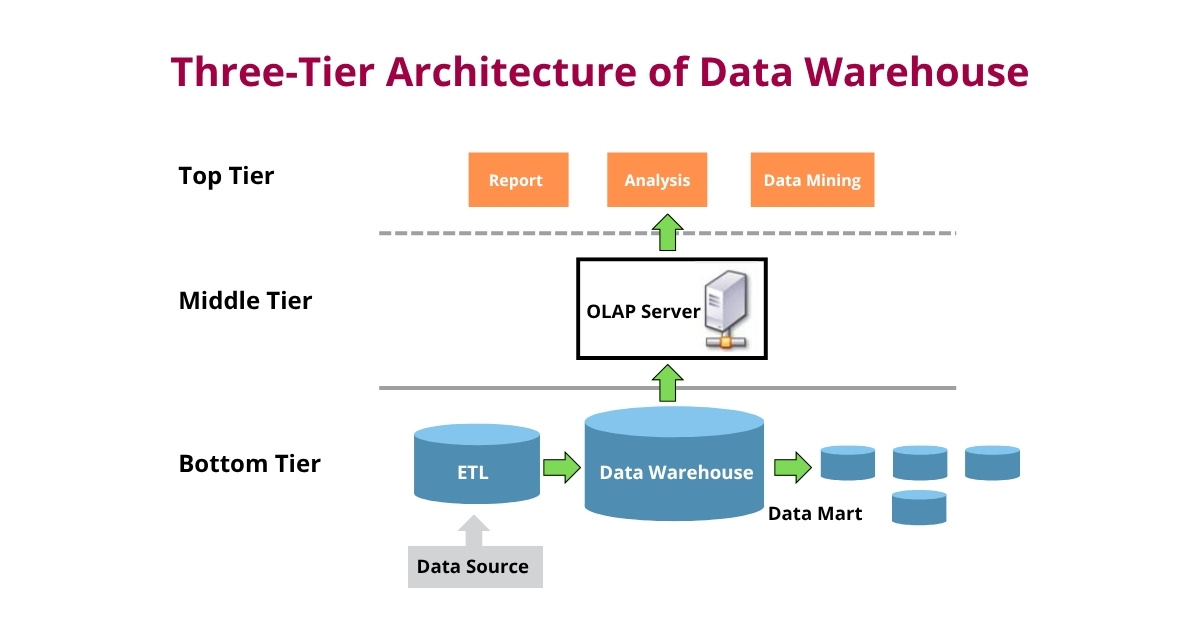
By adding another layer to the two-tier model, the three-tier architecture makes data retrieval more efficient, making it suitable for deployment in the most complex data environments. Another notable aspect is that each department can access and analyse data to meet their specific requirements. Data configuration during ERP implementation especially enables departmental data access for analysis.
Thus, the three-tier architecture divides data processing into three layers, i.e. the bottom tier, the middle tier and the top tier, each containing different components of data warehouse, crucial for supporting the structure of the data warehouse.
+ Bottom tier
Also known as the data layer, the bottom tier extracts data from various sources, such as operational systems (OLTP), ERP systems, transactional systems, and external APIs, which is processed via the ETL process. The bottom tier also involves data storage in a relational database, providing support for structured analysis, leading to faster query responses.
+ Middle tier
Acting as a connecting layer between the bottom tier and the top tier, the middle tier hosts the online analytical processing (OLAP) server. This server can quickly retrieve massive data from the warehouse and ensure it is prepared for analysis. This is also referred to as the semantics layer.
+ Top tier
The top tier, known as the analytics layer, comprises front-end business intelligence tools facing the user. Via this layer, business analysts can easily interact with the stored data and meet their multiple ERP reporting requirements. Besides, this tier is essential for visual data analysis through graphs and charts.
How to Build a Data Warehouse?
Building a data warehouse involves a step-by-step approach, taking into account your objectives and existing IT infrastructure. To make this process successful, follow these steps.
- Gather information: Involving the top leaders of the company is a crucial first step to understand both short- and long-term business objectives. Find out how compatible your IT infrastructure is to build a data warehouse. What is the quality of the data available?
- Identify data sources: A data warehouse extracts data from multiple sources. Define what databases you will need to meet your intended goals and KPIs. As data formats may vary across databases, it will establish your choice of data integration method.
- Warehouse architecture: How your data warehouse is architected will depend on data volume and the complexity of your business decisions. Accordingly, you will need to choose from one-tier, two-tier and three-tier architecture.
- ETL Strategy: ETL processes offer the much-needed support for extracting, cleaning and transforming data before it is loaded into the data warehouse. From using the right ETL tool to designing the ETL workflow, you will need a proper plan for foolproof execution.
- Data models and schema: Data models establish a relationship between data within the warehouse. The choice is based on query complexity and the performance required. A schema is the backbone for a data warehouse structure. How fast you want to extract data will govern its selection.
- Testing and Deployment: After you have finalised all the components, it is time to build, deploy and test the capabilities of the data warehouse. Run the system by executing complex queries to check if it can meet your business intelligence objectives.
- Monitoring: You will need to continually update and maintain the warehouse to make sure that the system runs without snags. As you scale, your data analytics requirements also evolve. You will have to ensure the system is scalable and flexible to deliver the insights you are looking for.
Data Warehouse Example in Manufacturing
As manufacturers automate their operations through the use of computerised machinery and advanced technology like manufacturing ERP software, they require a data warehouse to collect, store and analyse large volumes of data.
Data sources for a state-of-the-art manufacturing company may include IoT sensors, cameras used for quality checks, and ERP systems that contain customer/vendor information, quality records, production line data, equipment maintenance data, inventory data, and financial records.
Modern data warehouses facilitate the integration and analysis of all this data, including current and historical data, to make strategic business decisions. Consequently, manufacturers can:
- Make decisions on inventory levels throughout the supply chain
- Prevent equipment failure through predictive maintenance
- Improve production scheduling and re-optimise resources
- Forecast sales by factoring in past sales data and market trends
- Enhance product design and quality by analysing customer orders and feedback.
![]()
Conclusion
Given the multifold advantages of data warehouses, businesses are increasingly deploying them as part of their growth strategy. It allows them to analyse extensive historical records and identify patterns, leading to continuous improvement in business performance through better decisions.
Sage X3 ERP solution streamlines data warehousing set up and management for businesses with multiple data sources and complex analytical queries. Advanced capabilities across data modelling, ETL processes, business intelligence and data quality and governance make Sage X3 a go-to solution for in-depth reporting and analytics.

Data Warehouse FAQs
1. What is a Cloud Data Warehouse?
Cloud data warehouse refers to data warehouse solutions where the databases are hosted and managed on the cloud, ensuring faster scalability, flexibility and enhanced collaboration for real-time data analysis.
2. What is the Difference Between a Data Warehouse and a Data Lake?
A data warehouse contains highly structured data that has been formatted and transformed to meet defined business objectives. A data lake contains a mix of unstructured data, semi-structured data and structured data that can be used for wider, undefined purposes.
3. What is the Difference Between a Data Warehouse and a Database?
A data warehouse stores vast data from multiple applications and is specifically built for business intelligence and analytics. In contrast, a database is an application-specific data source, which may supply data to the data warehouse.
4. What is the Difference Between a Data Warehouse and a Data Mart?
An enterprise data warehouse (EDW) aggregates multiple databases, supporting data analytics requirements for the entire organisation. A data mart is a smaller subset of a data warehouse, containing data for a specific business area like sales, finance or inventory.